Sharing the memory load
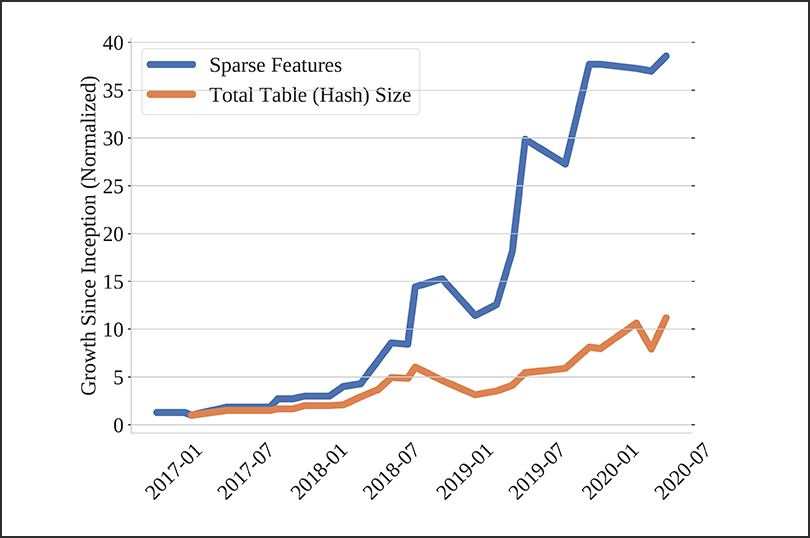
Across industries, the size of deep learning recommendation models is growing in leaps and bounds. As the quest for increased accuracy drives change—since larger models often translate into improved recommendation accuracy—technology companies like Google, Facebook, and Baidu have documented size growth of recommendation models and the challenges that arise.
One prominent challenge: with model sizes increasing, the traditional method of loading an entire model to a single server is becoming less and less viable. One server is no longer able to support the terabytes of space now needed.
Associate Professor Mark Hempstead of the Tufts Department of Electrical and Computer Engineering is working with colleagues to develop solutions for models’ increasing server space needs. In a new paper published at the 2021 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), corresponding author Hempstead, first author Michael Lui, PhD student at Drexel University (co-advised by Hempstead), and a team of Facebook colleagues—Yavuz Yetim, Özgür Özkan, Zhuoran Zhao, Shin-Yeh Tsai, and Carole-Jean Wu—used data-center serving infrastructure to study the practice of scaling out a large model’s memory requirements across multiple servers, called distributed inference.
The group evaluated three embedding table mapping strategies on three representation models, after finding that a model’s static embedding table distribution was key to the effects of distributing a model across servers. The team showed how efficiency improvements in data-center scale recommendation serving can be driven by distributed inference.
The paper was honored for its impact with a nomination for the ISPASS 2021 Best Paper Award. The research serves as a crucial first step for a systems community just beginning to turn its attention to the system challenges and design space opportunities posed by the growth of deep learning recommendation models.
Department:
Electrical and Computer Engineering